对比学习在CV与NLP领域的研究进展与技术发展
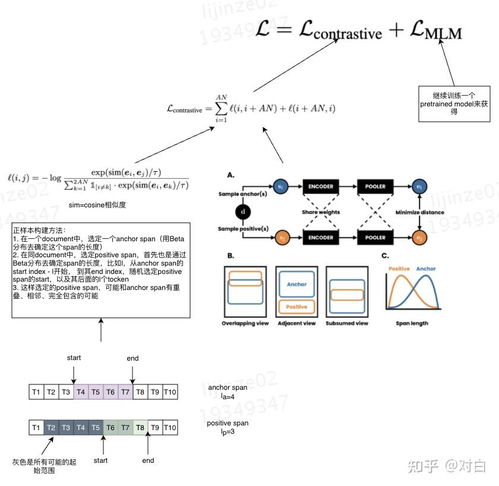
对比学习作为一种自监督学习方法,近年来在计算机视觉和自然语言处理领域取得了突破性进展。它通过拉近相似样本、推远不相似样本的方式学习数据的表征,显著提升了模型在无标注或少量标注数据上的性能。
一、计算机视觉领域的研究进展
在CV领域,对比学习最初通过SimCLR、MoCo等框架展现了强大潜力。SimCLR通过数据增强构建正样本对,利用NT-Xent损失函数进行优化;MoCo则引入动量编码器和动态队列,稳定了负样本的对比过程。BYOL和SimSiam进一步探索了无需负样本的对比学习范式,通过预测头架构和停止梯度操作避免了模型坍塌问题。这些方法在ImageNet等基准数据集上取得了与监督学习相媲美的性能,并推动了目标检测、语义分割等下游任务的进步。近期研究聚焦于多模态对比学习(如CLIP),通过图像-文本对训练实现零样本泛化能力,极大拓展了应用边界。
二、自然语言处理领域的技术演进
NLP领域早期通过Word2Vec的Skip-gram模型隐含了对比思想,而真正突破始于SimCSE和BERT对比学习变体。SimCSE通过Dropout噪声构建句子级正样本,显著提升了语义相似度计算效果。InfoWord、DeCLUTR等工作则针对词、句级别表征进行对比优化。关键进展体现在:1)结合掩码语言建模的混合预训练策略(如ELECTRA);2)跨模态对比学习(如VisualBERT),对齐视觉与语言表征;3)提示学习与对比结合,提升小样本场景性能。当前,对比学习已成为提升预训练语言模型鲁棒性和语义理解能力的重要手段。
三、核心技术创新与试验发展
- 负样本处理技术:从大规模负样本队列(MoCo)到基于聚类的原型对比(SwAV),再到完全消除负样本的方法,研究者不断优化计算效率与表征质量平衡。
- 损失函数设计:InfoNCE损失成为主流,其温度参数调节成为研究热点;Triplet Loss、Circle Loss等变体针对困难样本优化。
- 数据增强策略:CV领域依赖裁剪、色彩抖动等图像增强;NLP领域则探索回译、词替换等文本增强方法,但文本语义保持仍是挑战。
- 理论突破:对比学习与互信息最大化的理论联系被深入探讨,最近的研究揭示了梯度一致性与表征坍缩的内在机制。
- 跨领域融合:多模态对比框架(如ALIGN)通过数十亿级图像-文本对训练,实现了开放域理解能力的飞跃。
四、挑战与未来方向
尽管成果显著,对比学习仍面临诸多挑战:1)对数据增强的高度依赖限制了领域适应性;2)负样本在高度相似场景中的判别困境;3)计算资源消耗巨大。未来趋势可能包括:
- 轻量化对比框架设计,降低计算门槛
- 结合因果推理提升表征可解释性
- 探索量子化对比学习等新型优化范式
- 在医疗影像、科学文献分析等垂直领域的深化应用
对比学习通过不断创新的技术路径,正在重塑CV与NLP领域的表征学习范式。随着理论体系的完善与跨学科融合的深入,其有望成为通向通用人工智能的关键基石之一。
如若转载,请注明出处:http://www.tss008.com/product/70.html
更新时间:2026-06-19 20:08:30